

The Dawn of a New Era: OpenAI’s o3 Model Surpasses the Best of Us
Last night, OpenAI dropped a bombshell: the unveiling of their groundbreaking reasoning model, o3. Whatever you've thinked about AI - rethink it.
The o3 model isn’t merely competent; it’s outperforming some of the brightest human minds across mathematics, science, and coding—domains we’ve long held as bastions of human ingenuity.
A Leap Beyond State-of-the-Art
Let’s start with the astounding results. Here’s what o3 has achieved across different benchmarks:
Mathematics (FrontierMath)
- Achieved 25.2% on ultra-hard problems that stump even professional mathematicians.
The FrontierMath test is a benchmark designed to evaluate an AI's ability to tackle extremely complex and abstract mathematical problems, far beyond the scope of traditional math tests. These problems are deliberately constructed to be challenging even for professional mathematicians, often requiring deep conceptual understanding and creative problem-solving. Unlike standard benchmarks, which include widely studied problems, FrontierMath presents entirely new, unpublished challenges, ensuring that success cannot rely on memorized solutions or pre-existing datasets.
For Large Language Models (LLMs), FrontierMath is particularly difficult because it requires more than recognizing patterns or applying well-known formulas. It demands the ability to reason through intricate relationships, construct multi-step solutions, and avoid pitfalls like guesswork, which is rendered ineffective by the test's design. This makes FrontierMath a true test of an AI’s mathematical reasoning capabilities rather than its training scale or computational power.
And current AIs, even the most recent one, struggle with this test. The best of them can barely reach 2%.

The FrontierMath test is an exceptionally challenging benchmark, specifically designed to push the limits of mathematical reasoning. Average humans typically perform also very poorly on this test, often scoring close to 0%, unless they have advanced mathematical training. Even professional mathematicians might find many of these problems daunting, as they are crafted to require deep conceptual understanding and innovative problem-solving approaches. Mathematicians with expertise in the relevant areas might score around 30%-50%, depending on the specific problems and their familiarity with the subject matter.
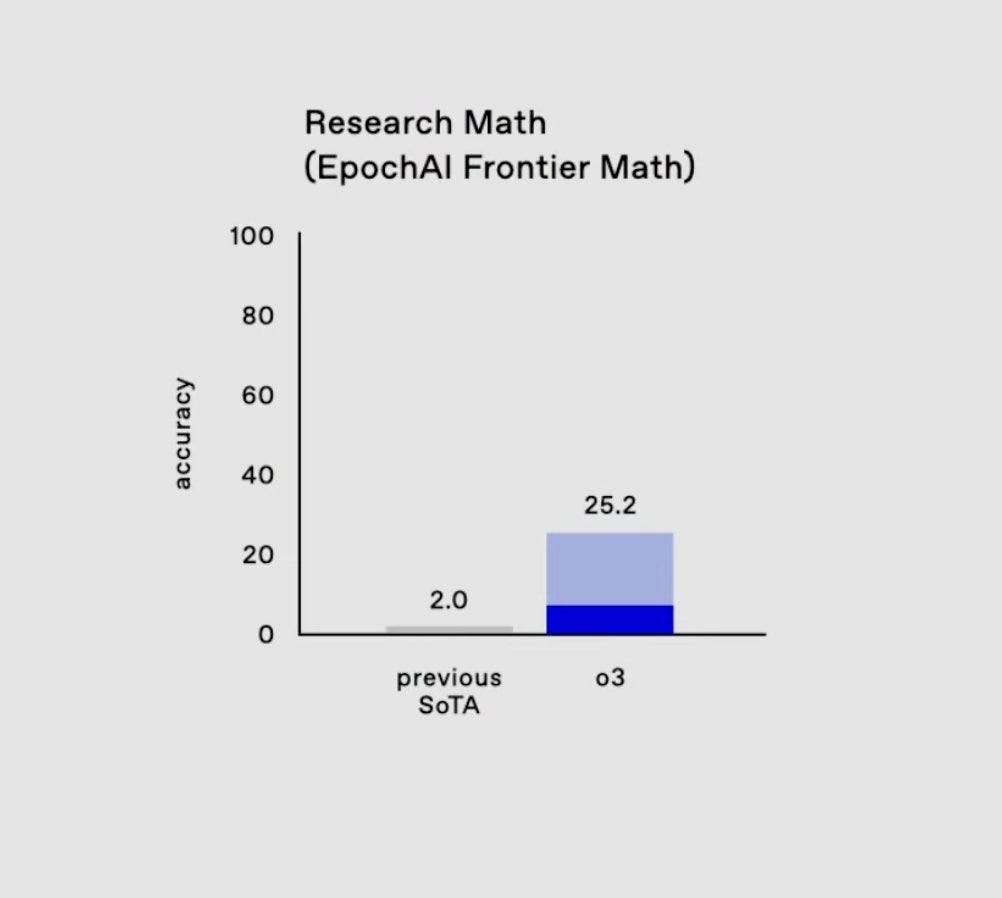
OpenAI’s o3 achieving 25.2% on this benchmark is groundbreaking, as prior state-of-the-art models barely reached 2%. This leap suggests a level of mathematical reasoning approaching that of experts who might spend hours or days solving these problems. It marks significant progress in AI's ability to handle abstract reasoning, a critical step toward solving real-world scientific and mathematical challenges.
AIME Math Test (High School Level)
- Achieved 96.7% accuracy, typically missing only one question out of 15.
The AIME Math Test (American Invitational Mathematics Examination) is a high school-level competition featuring 15 exceptionally challenging problems. It is part of the qualification process for the prestigious USA Mathematical Olympiad and is designed for students who have already excelled in earlier rounds. With a three-hour time limit and no calculators allowed, the test covers advanced topics in algebra, geometry, number theory, and combinatorics, requiring creative problem-solving and multi-step reasoning. Most participants, even highly skilled ones, rarely achieve perfect scores, with a score of 10 or higher considered exceptional.
OpenAI’s o3 model achieved a remarkable 96.7% accuracy on AIME, typically missing only one question. This performance is on par with the best human competitors, showcasing an extraordinary level of mathematical reasoning and consistency across diverse problems. Unlike previous models that relied on pattern recognition, o3 demonstrates an ability to reason through complex tasks with near-human precision. With benchmarks like AIME approaching saturation, this result underscores o3’s capability to operate at the limits of what these tests can measure, marking another step toward AI exceeding human problem-solving expertise in structured, advanced domains.
Graduate-Level Science (GPQA Diamond)
- Scored 87.7%, outperforming the average PhD expert who scores around 70% in their own field.
The GPQA Diamond test (Graduate-level “Google-Proof Q&A”) is a benchmark designed to evaluate an AI’s ability to reason through and answer highly complex, specialized science and academic questions. These questions are deliberately crafted to be beyond simple fact retrieval, requiring deep understanding, synthesis of information, and conceptual reasoning across graduate-level topics.
Standard LLMs (state-of-the-art or SoTA models) struggle with GPQA Diamond because it explicitly challenges their core limitations:
No reliance on memorized knowledge: The questions are “Google-proof,” meaning they often involve novel problems or require reasoning not explicitly covered in training data.
Complexity of reasoning: Answers typically demand multi-step logical deduction, domain expertise, and the ability to generalize across disciplines.
Absence of shortcuts: Unlike fact-based benchmarks, GPQA Diamond requires models to engage in abstract reasoning and problem-solving, which LLMs historically find difficult due to their reliance on pattern recognition rather than true understanding.
Graduate students and PhDs, especially those working in the field of the questions being asked, average around 70% on GPQA Diamond. This reflects their specialized training and ability to reason through complex, academic problems. However, even they may struggle with questions outside their immediate expertise or when asked to synthesize knowledge from multiple domains.
For an average person without advanced training, the score would be much lower, likely below 30%, as the test requires not just general knowledge but the ability to reason through challenging and unfamiliar concepts.
The o3 model took a significant leap from the previous models - within a few weeks.
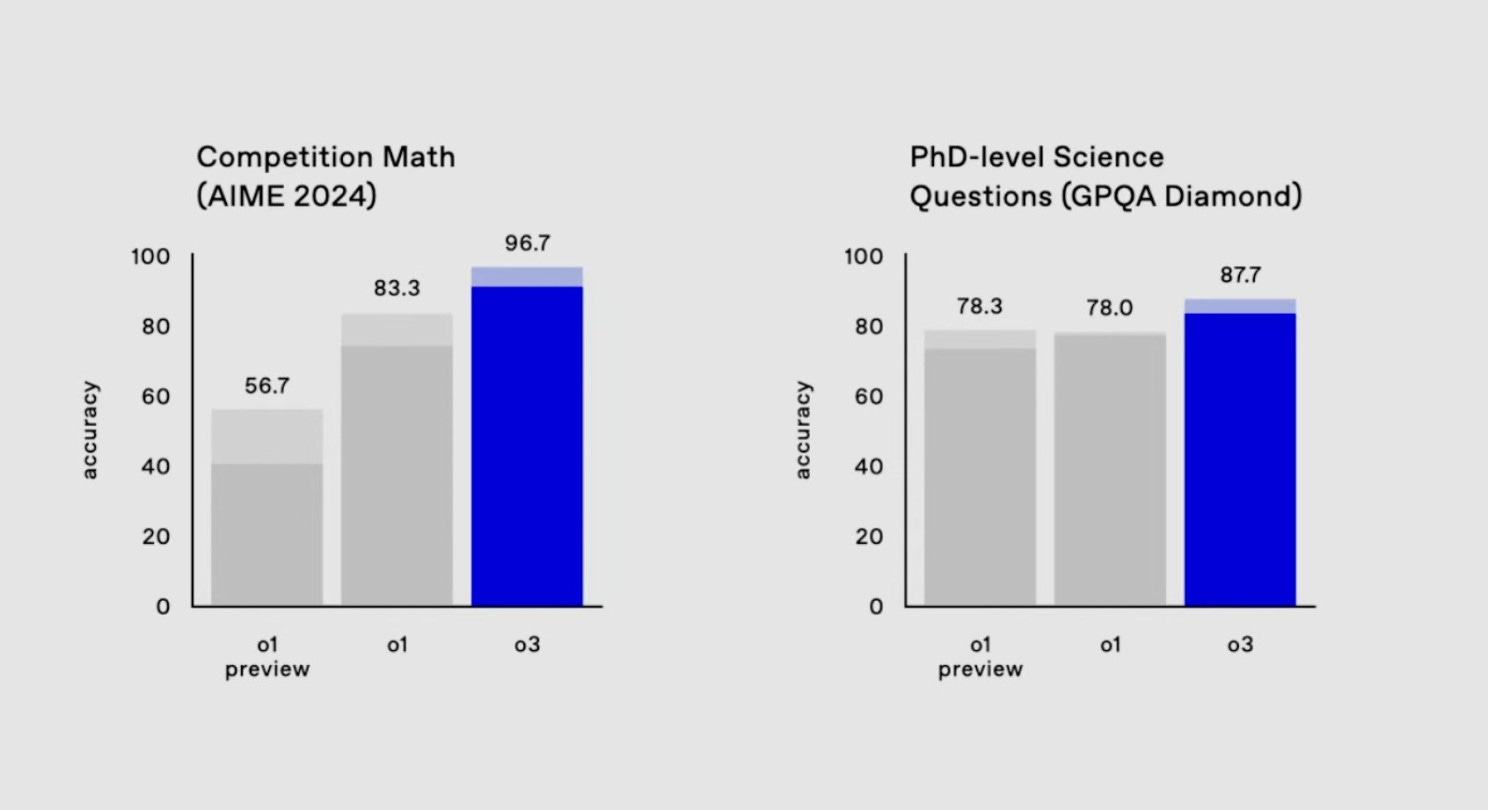
OpenAIs o3 model is smarter than most of humanity. Wow.
Competitive Coding (Codeforces)
- Reached an Elo score of 2727, ranking among the top 200 competitive programmers globally.
- Surpassed the 99.95th percentile of human coders, including some of OpenAI’s own researchers.
Codeforces is one of the most prestigious platforms for competitive programming, where participants solve complex algorithmic problems under time constraints. These problems require advanced coding skills, logical reasoning, and the ability to quickly devise and implement efficient solutions. It is widely regarded as a gold standard for assessing a programmer’s ability to tackle real-world computational challenges.
Participants on Codeforces are ranked using an Elo rating system, similar to chess, which measures their relative skill based on performance in contests. Reaching the top 200 competitors globally is an extraordinary achievement, as these individuals represent the pinnacle of human capability in algorithmic thinking and programming.
OpenAI’s o3 model achieved an Elo score of 2727, placing it firmly within this elite group. This performance means that o3 surpassed the 99.95th percentile of human coders, a level of expertise that includes some of OpenAI’s own top researchers. The significance of this achievement lies not only in the raw score but in what it represents: o3 is not merely following learned patterns but actively solving novel problems with speed and precision that rival the world’s best human programmers.
This result highlights a monumental leap in AI’s capabilities in coding, a domain once thought to be resistant to automation at the highest levels. With this performance, o3 demonstrates its potential to revolutionize fields reliant on algorithm design and implementation, setting a new standard for what AI can achieve in competitive programming and beyond.
Reasoning (ARC-AGI Benchmark)
- Scored 88%, up from 5% earlier this year.
- Outperformed models that were considered state-of-the-art just months ago.
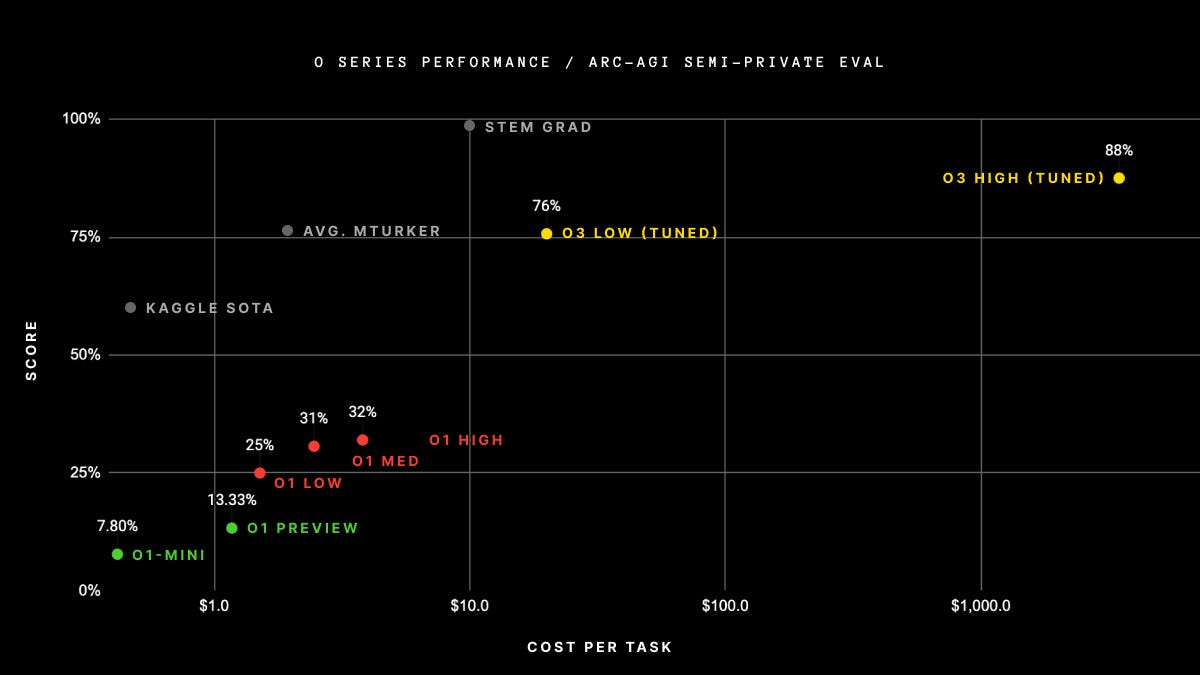
The ARC-AGI Benchmark challenges Large Language Models (LLMs) because it tests their ability to reason abstractly and solve novel problems, rather than rely on patterns or data from training. Unlike traditional tasks, ARC-AGI is “Google-proof,” requiring models to infer unseen rules and apply them in unfamiliar contexts. For example, it often involves recognizing patterns in input-output transformations and extrapolating those rules to new scenarios—something humans find intuitive but LLMs struggle with.
This difficulty stems from the fact that LLMs excel at interpolating within known data but falter when asked to generalize beyond it. They lack the cognitive creativity to infer new rules, a skill deeply tied to human reasoning. ARC-AGI tasks expose this limitation, highlighting the gap between statistical pattern recognition and true general problem-solving. OpenAI’s o3 surpassing earlier models on ARC-AGI marks a significant leap, bringing us closer to AI systems capable of human-like reasoning.
On the ARC-AGI Benchmark, the performance of average humans typically ranges between 70% and 80%, depending on their familiarity with abstract reasoning tasks and problem-solving skills.
"These are extremely challenging ... I think they will resist AIs for several years at least." - Terence Tao, mathematician
LLMs took 4 years to get from 0 to 5% in this test from 2020 until the beginning of 2024. Then it took another 9 months to reach around 35%. And another 3 to get to 88%, which is far beyond average humans. Do you see the exponential pattern?
Why This Marks a New Era
These results signify far more than technical excellence. They represent a shift where AI no longer just assists humans but begins to surpass nearly all of us in cognitive tasks.
The rapid advancements of OpenAI’s o3 model suggest that artificial general intelligence (AGI) may be closer than we anticipate. Earlier AI models required years of training and refinement to achieve significant progress. In contrast, o3’s ability to improve during inference time allows for faster iterations and continuous enhancements. This shift accelerates the development cycle dramatically.
The improvement curve for o3 is steepening in ways that are hard to ignore. In under a year, it leaped from 5% to 88% on the ARC-AGI benchmark and from 2.0% to 25.2% on the ultra-difficult FrontierMath test. These are not merely incremental gains—they are exponential. Moreover, o3’s versatility across domains, from coding to abstract reasoning, signals that a unified intelligence capable of mastering diverse tasks is within reach.
Economic scalability also plays a crucial role in o3’s promise. The cost of achieving high-performance results with AI models has plummeted in recent years. For instance, when GPT-4 launched in March 2023, generating high-quality outputs cost around $36 per million tokens. By late 2024, competing solutions, like China’s DeepSeek, were offering similar quality for as low as $0.14 per million tokens—a staggering 250-fold reduction. These trends suggest that what currently costs thousands of dollars per query, as seen with o3’s most advanced settings, could become affordable within a few years. Such a shift would enable tools like o3 to become widely accessible, driving innovation and integration across industries at an unprecedented pace.
The implications of o3’s capabilities are profound. In science and engineering, it has the potential to tackle problems in areas like category theory and higher-dimensional algebra—challenges that are far beyond everyday human comprehension. By augmenting expert capabilities, o3 can unlock faster innovation and discovery. As benchmarks like ARC-AGI and GPQA fall, the barriers to AGI are rapidly diminishing, suggesting that the emergence of AI rivaling human general intelligence could happen within the next few years.
Looking ahead, the role of AI in solving humanity’s greatest challenges cannot be overstated. From addressing climate change to advancing medical breakthroughs and optimizing global resource management, models like o3 could provide solutions to problems that have long seemed insurmountable. Once AI systems reach the point where they can improve themselves—an inflection point known as recursive self-improvement—the pace of development could accelerate exponentially. In such a scenario, progress that currently takes years could be compressed into days, or even hours, potentially bringing about the singularity—a moment where AI surpasses human intelligence in every domain. This transformative possibility underscores the need for careful stewardship and ethical considerations as we approach this unprecedented future.
Merry Christmas, and welcome to the new era of AI.